DIY Support Chatbots: Creating Your First AI Assistant on Your Own Documentation
Get ready to build a reliable, context-aware chatbot that won't make things up and will keep your users engaged on you own documentation! Dive into the world of support chatbots with this guide! Learn how to harness the power of Python, Langchain, and OpenAI API to create a customized AI assistant.
Introduction
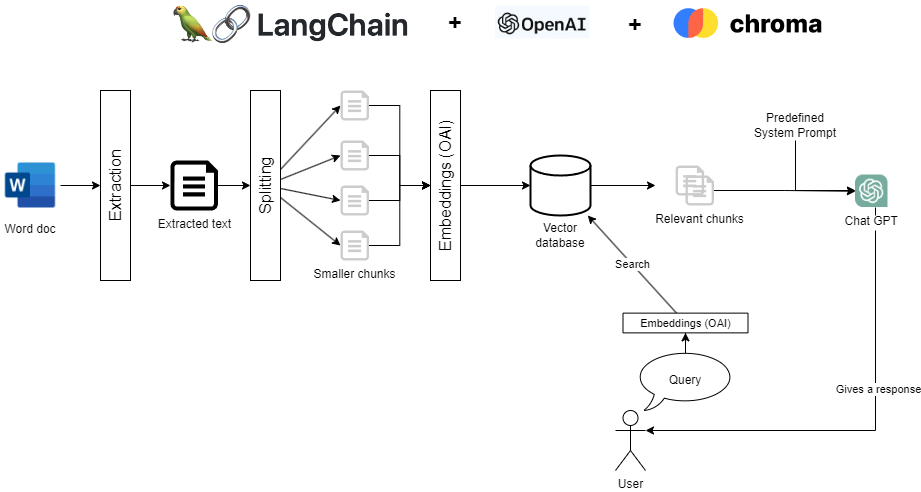
In this blog post, I'll guide you through the process of creating your own AI-powered support chatbot that utilizes your existing documentation to provide accurate assistance. This guide is my way of participating into the current ChatGPT movement, explaining with my own words how to easily get into the subject and understand the basics.
By leveraging Python, Langchain, and the OpenAI API, I'll demonstrate how to transform your documentation into valuable assets for your chatbot. We'll cover the steps of breaking down your documents into chunks, converting them into embeddings, and storing them in ChromaDB. This approach enables your chatbot to access the information it needs to deliver context-based answers effectively.
Moreover, I'll discuss the best practices for crafting a context-aware ChatGPT prompt, ensuring your chatbot offers reliable and helpful responses without making things up.
Join me on this journey to create a support chatbot that not only engages users but also enhances your customer support experience. Let's dive in and learn valuable skills along the way!
Setting up the development Environment
Before diving into the exciting world of chatbot development, it's crucial to set up the right development environment. Having the proper tools and configurations in place ensures a smooth and efficient development process, allowing you to focus on building your AI-powered support chatbot.
We'll walk through the essential tools, libraries, and APIs you'll need to get started. We'll also cover the installation process and guide you through setting up API keys.
Required Tools, Libraries, and APIs
To create your support chatbot, you'll need the following:
- Python: A versatile programming language that's widely used in AI and chatbot development. Download the latest version of Python from the official website: https://www.python.org/downloads/
- Langchain: A powerful tool for working with text data, particularly when it comes to splitting and managing document chunks. It has also become an essential part of chaining actions towards Open AI API like ChatGPT.
- OpenAI API: The OpenAI API provides access to powerful language models like GPT-3 / GPT-4 and more recently ChatGPT, which we'll use for document embedding and chatbot response generation. To get started with the OpenAI API, visit the OpenAI website and sign up for an account to get your own API key : https://platform.openai.com/. Beware that you will be charged for using this API so make sure not to use too huge amount of data for your first tests and watch closely your API consumption.
Installation Process
Once you've downloaded Python, follow these steps to install Langchain, Chroma and set up the OpenAI API:
- Install pip dependencies: Open a terminal or command prompt and run the following command:
# Langchain, the orchestrator for our chatbot
pip install langchain
# The vectore store Chroma Db
pip install chromadb
# Library to extract text from word document
pip install unstructured
This will install Langchain and its dependencies as long as Chroma, a vector database plus a little dependency to extract information out of a Word document.
- Set up the OpenAI API: After signing up for an OpenAI account, you have to create an API key from you account on the plateform.openai.com web site. For Linux and macOS, run the following command in your terminal:
export OPENAI_API_KEY="your_api_key_here"
For Windows, open a command prompt and run:
set OPENAI_API_KEY="your_api_key_here"
Remember to replace "your_api_key_here" with the actual API key you created from OpenAI plateform.
Now that you've set up your development environment, you're ready to start building your support chatbot. In the next chapter, we'll dive into the process of ingesting your documentation and converting it into embeddings using Python, Langchain, and the OpenAI API.
Ingesting and Processing your own documentation
Now that your development environment is all set, it's time to delve into the core of our support chatbot: ingesting and processing your documentation. I'll guide you through splitting your documents into manageable chunks, transforming them into embeddings using the OpenAI API, and storing them in ChromaDB for efficient retrieval.
Loading a documentation and splitting it into chunks
First, we need to break down your documentation into smaller, manageable chunks. This process will allow us to send to the chat bot only the relevant chunks as context so it is able to answer the question from the user.
Here is how you can load a Word document using langchain, don’t forget you will need the “unstructured” library.
from langchain.document_loaders.word_document import UnstructuredWordDocumentLoader
loader = UnstructuredWordDocumentLoader("user_doc_en.docx")
loaded_document = loader.load()
At the end of this method, loaded_document will contain an array of a single Document object containing all the content of your word file. Note that the data is not yet splitted at this stage and you can’t feed the whole document to ChatGPT as context (mainly because of input tokens limitations).
So the next part consists of splitting this big document into several smaller parts, using again langchain integrated capabilities.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splitted = splitter.split_documents(loaded_document)
This will split the document into smaller chunk of maximum 1000 characters. Know that the split is done in a smart way to keep sentences in the same chunk, you can get more details by reading the complete documentation of RecursiveCharacterTextSplitter by clicking here
On my example, I had 32 chunks for an original document of about 50 pages.
Create embeddings and store them locally
Next, we'll convert these text chunks into embeddings using the OpenAI API. These embeddings are compact numerical representations of the semantic of the test that makes it easy and blazingly fast to retrieve based on the semantic meaning of the chunks.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
# This line does a lot of stuff behind the scenes, it convert the chunks into
# embeddings, calling OpenAI API (watch for API costs !), then storing it locally
# into our Chroma database
doc_search = Chroma.from_documents(splitted, embeddings)
As you can see, langchain is helping a lot here to ease the whole process but you have to understand that behind the hood all those actions are done :
- Each chunk is sent to OpenAI embedding engine to transform each chunk into a vector of floating number, representing there semantic meaning.
- Each vector generated this way are stored in Chroma for later retrieval.
Please note that by default the Chroma storage is in memory and will not be persisted.
Handling User Queries and Generating Context-Aware Responses
With your documentation processed and stored in ChromaDB, it's time to bring your support chatbot to life. We will see how to handle user queries, matching them with relevant document chunks, and generating context-aware responses using ChatGPT.
Converting User Queries into Embeddings and get related chunks
When a user submits a query, we'll first need to convert it into an embedding to find the most relevant chunks in Chroma DB. Here's how to do this very easily with langchain :
retriever = doc_search.as_retriever()
query = """How to delete my account ?"""
# This line again does a bunch of stuff like querying OpenAI API
# to transform the query into embedding and then compare it to all the embeddings
# stored in the local Chroma DB to find the most relevant piece of documentations
relevant_docs = retriever.get_relevant_documents(query)
At the exit of this code, you will have 4 (number by default) chunks extracted from the Chroma DB that are semantically the closest to the user query. They are the 4 chunks we will provide to ChatGPT to be able to answer our user’s question with the right context.
Generating Context-Aware Responses with ChatGPT
With the relevant chunks identified, we'll now use them as context to generate a response from ChatGPT, the key part of this step is to provide a good System prompt that will make ChatGPT behave as you expect it to.
I put here an example but there are a lot of resources on the internet to improve and adapt it the way you need.
from langchain.chat_models import ChatOpenAI
from langchain.schema import (SystemMessage, HumanMessage)
# The temperature at 0 here will prevent the chatbot to go wild on the responses
# and stay more pragmatic.
chat = ChatOpenAI(temperature=0)
# Concatenate all the relevant chunks identified previously
only_contents = map(lambda d : d.page_content, relevant_docs)
concatenated_found_docs = '\\n'.join(only_contents)
# The system prompt is the most important thing to focus your chat bot
# On top of the context, you should specify the behavior you want it to adopt
# In front of the context, instruct the AI to
systemMessage = SystemMessage(content= """
You are a very clever AI assistant that shall only respond to questions about <Your product Name> and <Your app domain> subjects.
You are very polite and joyfull.
I will give you several part of document that you will use as a context to forge your answer.
We will never try to guess or invent anything if you don't have the information in the context.
If this case happens, you will simply answer in the appropriate language "I'm sorry I don't have the appropriate knowledge, you can contact the support team on support@myapp.com to get a full answer to your question"
Now here are the context sentences : """ + concatenated_found_docs)
# Encapsulate the user query in a HumanMessage
humanMessage = HumanMessage(content=query)
# Request the chat response providing in the right order SystemMessage + HumanMessage
chat_result = chat([systemMessage, humanMessage])
Chat GPT 3.5 will be used as a default model but if you have access to it, you can specify the model ‘gpt-4’ in the ChatOpenAI constructor, especially because it is much better at being constrained by the System Prompt.
Your chatbot will now provide a response that takes into account the relevant information from your documentation and stay in line with your directives (hopefully !)
Conclusion
Congratulations on successfully building your very own support chatbot using Python, Langchain, OpenAI API, and ChromaDB! By following this guide, you've created a chatbot capable of providing context-aware answers based on your existing documentation. This chatbot has the potential to enhance your customer support experience, streamline your operations, and engage users effectively.
However, it's important to note that the chatbot we've built in this tutorial serves as a Proof of Concept (PoC). When transitioning to a production environment, there are several factors to consider and improvements to be made.
One key consideration is the choice of vector database. While we used ChromaDB for our example, there are numerous vector databases available with varying features, performance, and scalability. Careful evaluation and selection of the right database for your specific use case is essential for optimal performance and efficiency.
Furthermore, it's crucial to perform extensive testing to ensure that the chatbot's responses remain within the expected scope and align with your business requirements. This may involve refining the chatbot's similarity threshold, improving the quality of the input data, or fine-tuning the model's parameters or system prompt to achieve better response accuracy.
In conclusion, the chatbot built in this tutorial demonstrates the potential of AI-powered support chatbots using your own documentation. By taking this PoC as a starting point and addressing the considerations mentioned above, you can develop a production-ready solution that revolutionizes your customer support experience.
Good luck, and happy coding!